在高密度校园中,以认知 LLM-Agents 驱动群体的“出发–就餐窗口–方式–路径”联动决策,评估信息策略对群体队列与道路负载的再分配与峰值削减效果。
背景与价值 链接到标题
- 群体视角:统一刻画上万人在高峰期的链式决策并度量整体空间利用与峰值压力。
- 可解释:每次决策均附来源标签与理由,支持从个体到群体的因果溯源与模式归纳。
- 可干预:对比全局/碑牌等信息策略,量化群体排队事件与道路方差 σ 的改善幅度。
方法概览 链接到标题
- LLM Agent 的决策框架:决策框架:围绕“何时出发、去哪就餐、采用何种方式、沿何路径”的四类选择,弱耦合协同。每一步均承接上一步的短期记忆(STM)与环境快照,输出可解释的理由;个体层面可追踪,群体层面可聚合评估。
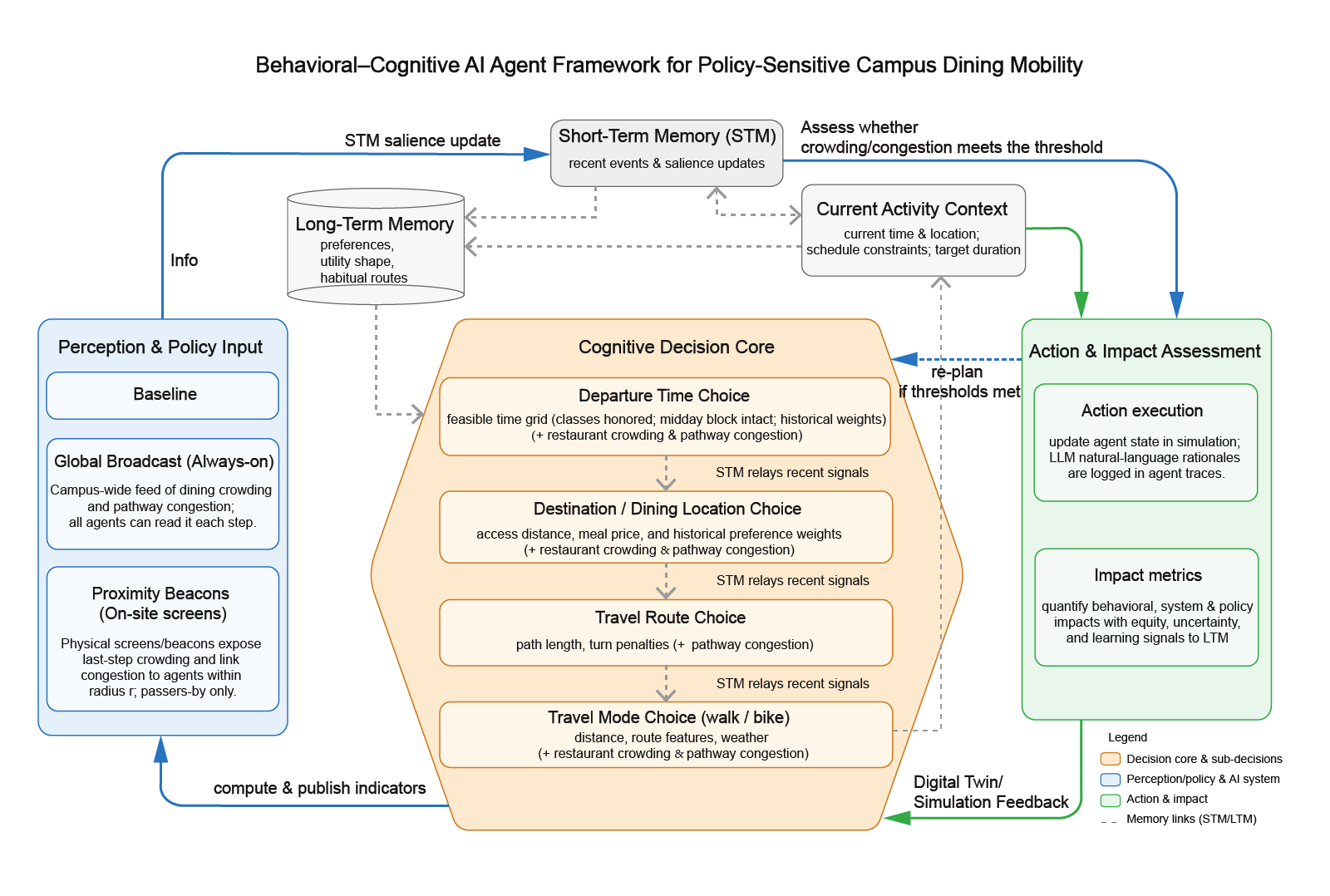
- 记忆与信息感知系统:以‘长期偏好摘要 + 近期事件’构成粘性记忆,逐步吸收对距离、价格、拥挤度与通行负载等要素的偏好;在相关信息策略开启时,餐厅拥挤与道路拥堵以‘上一仿真步(约5分钟之前)’的快照形式注入 LLM-Agent 的输入,用作当步决策的情境先验。
- 给 LLM 的提示词:
评估维度 含义 示例提示词表述(所属决策) 联合权衡(通用) 不设固定优先级,综合考虑时间、距离/价格、偏好、拥挤/拥堵与环境上下文 “Consider all signals jointly with no fixed priority.”(四类通用) 信息语义与来源(通用) 拥挤/拥堵为“上一仿真步”快照;未知≠为零;在理由中标注来源 “Crowding/road info are previous-step snapshots; unknown ≠ zero; tag provenance in reasons, e.g., [crowd_provenance: global_prev_step] / [road_provenance: beacon_prev_step]。”(四类通用) 公平性与可解释(通用) 避免无依据的身份推断;输出可追踪、可聚合的理由 “Fairness: avoid unsupported identity claims; provide transparent reasoning.”(四类通用) 显著性微调(通用) 作出小幅偏好更新,作为粘性记忆的温和调节,而非硬规则 “Apply small salience adjustments in [-0.15, 0.15] as gentle memory updates.”(四类通用) 可行性约束与网格(出发) 在允许时间网格内选择,严格满足课表边界;优先完整连续时段 “Choose from the allowed time grid under class constraints; prefer a contiguous block around the target length.”(出发) 近似等效时的裁决(出发) 候选短名单可作为软性平局裁决,必要时引入轻度随机一致性 “When options are close, use the shortlist as a soft tie-breaker, with a consistent stochastic token if needed.”(出发) 时间压力与偏好(就餐地点) 与距离/价格/个体偏好共同权衡;已知高拥挤(≈≥0.90)时更保守,但可在强理由下例外 “Balance distance, price, preferences, and time pressure; be conservative under clearly high crowding unless explicitly justified.”(就餐地点) 路线要素与天气(方式) 结合路程、拥堵总量、转弯数、天气与骑行开销;高拥堵时减少暴露 “Trade off distance, route features (length/congestion/turns), weather, and biking overhead; under high congestion, reduce exposure.”(方式) 长度—拥堵—转向(路径) 在总长度、拥堵(含可观测比例)与转向复杂度间共同优化;未知时避免过度自信 “Balance total length, known congestion (and coverage ratio), and turns; avoid overconfidence when congestion is unknown.”(路径)
研究区域与数据 链接到标题
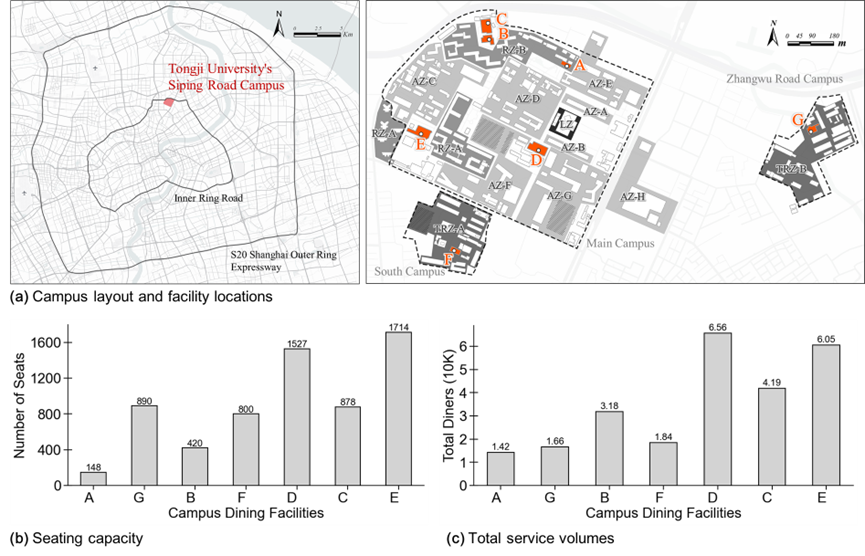
- 区域: 实证场地为同济大学四平路校区(上海,100.98 公顷,服务 31,653 人),为高密度校园,含 7 个餐饮场所与 16 个功能分区。
- 数据: 数据包括 2023 年 5 月 21 个工作日的校园一卡通日志(约 614 万条;午餐 10:00–13:30 时段覆盖约 27,800 人、约 25 万次就餐交易),并辅以 198 份行为偏好问卷(用时、策略接受度、信息意愿与可接受调整幅度等)。
使用与场景 链接到标题
使用功能与流程 链接到标题
选择信息策略(全局/道路/碑牌坐标与半径)→ 运行群体仿真 → 查看地图(轨迹/道路热度)、曲线(拥挤/队列)、日志(个体理由)→ 一键导出评估 HTML 与回放结果。
应用场景 链接到标题
将信息干预与需求侧政策(如错峰引导、方式/路径建议)嵌入群体行为仿真,量化对拥堵暴露、时间损失、可达性与公平性等指标的影响;后续拟扩展至供给侧情景(如动态定价、临时便当点布设),以支撑一体化政策评估与福利/弹性指标(如 VOT、消费剩余、需求弹性)估计。
研究核心结论 链接到标题
初步结果 链接到标题
LLM-Agent 日志展示(下表为不同信息情景下的简要对比)。
| Agent | 策略情景 | 理由 |
|---|---|---|
| 1 | NONE | Depart 11:50;Place 北苑_107;Mode walk;在允许时间网格内选取连续30分钟块;距离与既有偏好占优;UNKNOWN 拥挤不作乐观假设(UNKNOWN≠0)。 |
| 1 | GLOBAL | Depart 11:50;Place 西苑_203;Mode walk;全局快照显示 11:50–12:00 北苑拥挤上升 ⇒ 侧向转移至相近距离窗口;保持 30 分钟完整性。[prov: global_prev_step] |
| 2 | NONE | Depart 11:10;Place 北苑_105;Mode walk;为避开 11:30 下课拥堵提前出发;时间网格可行且步行成本最低。 |
| 2 | GLOBAL | Depart 11:20;Place 北苑_201;Mode walk;全局信息提示 11:10–11:20 段拥挤更高 ⇒ 在网格内右移10分钟并换相邻窗口,仍满足连续时段与到课前约束。[prov: global_prev_step] |
| 3 | NONE | Depart 12:00;Place 西苑_203;Mode walk;正午偏好与距离折中;未知拥挤不按低值处理。 |
| 3 | GLOBAL | Depart 12:00;Place 西苑_205;Mode walk;全局快照显示 203 队列增长、205 略低 ⇒ 同区微调窗口以降低等待,保持出发时刻与行程完整性。[prov: global_prev_step] |